












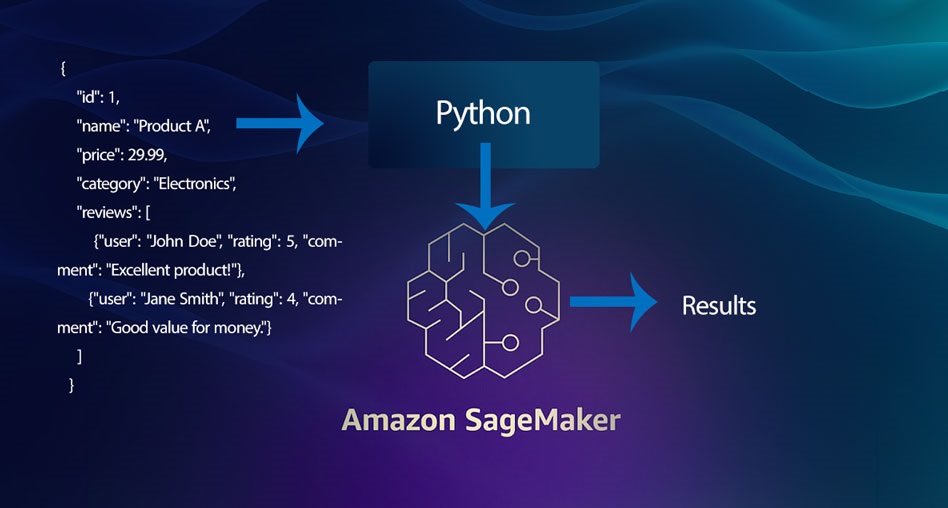
Performing Data Analysis with JSON Data Using AWS SageMaker. In today’s data-driven world, businesses often need to analyze large amounts of structured and unstructured data. JSON (JavaScript Object Notation) has become a popular format for storing and transmitting data due to its lightweight and flexible nature. AWS SageMaker, Amazon’s comprehensive machine learning service, allows you to build, train, and deploy machine learning models at scale. In this article, we’ll explore how to perform data analysis using JSON data as input to AWS SageMaker.
Understanding JSON and Its Use Cases
JSON is a text-based format used to represent data objects consisting of key-value pairs. It is widely used for APIs, configuration files, and data interchange between web applications and servers. JSON’s flexibility allows it to represent complex nested structures, making it ideal for various use cases, including:
- Web and Mobile Applications: JSON is often used to transmit data between a server and a client.
- Configuration Files: Many applications use JSON to store configuration settings.
- Data Storage: JSON is used in NoSQL databases like MongoDB to store semi-structured data.
Introduction to AWS SageMaker
AWS SageMaker is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy machine learning models quickly. It simplifies the machine learning process by offering pre-built algorithms, Jupyter notebooks, and the ability to run custom code for any use case.
Step-by-Step Guide: Analyzing JSON Data with SageMaker
- Preparing the JSON Data:
- Ensure that your JSON data is well-structured and clean. JSON data can be stored in Amazon S3 (Simple Storage Service) for easy access by SageMaker. Each JSON file should contain the relevant data that you want to analyze or use for training your machine learning model.
{
"id": 1,
"name": "Product A",
"price": 29.99,
"category": "Electronics",
"reviews": [
{"user": "John Doe", "rating": 5, "comment": "Excellent product!"},
{"user": "Jane Smith", "rating": 4, "comment": "Good value for money."}
]
}- Loading JSON Data into SageMaker:
- Use a SageMaker notebook instance to load the JSON data. You can use Python’s built-in
jsonlibrary to parse the data or libraries likepandasfor more complex operations.
import json
import boto3
import pandas as pd
s3_client = boto3.client('s3')
s3_response = s3_client.get_object(Bucket='your-bucket-name', Key='data.json')
json_data = json.loads(s3_response['Body'].read().decode('utf-8'))
# Convert JSON to DataFrame for analysis
df = pd.json_normalize(json_data)
print(df.head())- Data Exploration and Preprocessing:
- Once the data is loaded into a DataFrame, you can begin exploring it. Use descriptive statistics, visualization, and other data exploration techniques to understand the data.
- Preprocessing steps like handling missing values, normalizing data, and feature engineering can be done using SageMaker’s built-in tools or libraries like
scikit-learn.
# Basic data exploration
print(df.describe())
print(df.info())
# Preprocessing: Handling missing values
df.fillna(0, inplace=True)
# Feature engineering: Extract features from nested JSON
df['average_rating'] = df['reviews'].apply(lambda x: sum([r['rating'] for r in x]) / len(x))- Training a Machine Learning Model:
- With the data preprocessed, you can now train a machine learning model. SageMaker supports various built-in algorithms or you can use your own custom model.
- For instance, you can train a model to predict product prices based on features extracted from the JSON data.
from sagemaker.sklearn.estimator import SKLearn
# Define a SageMaker estimator
sklearn_estimator = SKLearn(
entry_point='train.py',
role='your-iam-role',
instance_type='ml.m5.large',
framework_version='0.23-1'
)
# Train the model
sklearn_estimator.fit({'train': 's3://your-bucket-name/training-data/'})- Deploying the Model:
- Once the model is trained, you can deploy it to a SageMaker endpoint for real-time predictions or use batch transform for large-scale inference.
- JSON data can be sent directly to the deployed model for predictions.
predictor = sklearn_estimator.deploy(instance_type='ml.m5.large')
# Making predictions with JSON input
result = predictor.predict(json.dumps({"price": 29.99, "category": "Electronics", "average_rating": 4.5}))
print(result)- Analyzing the Results:
- After getting predictions, you can analyze the results to derive actionable insights. Use SageMaker’s capabilities to monitor the model’s performance and retrain it as needed.
Benefits of Using SageMaker with JSON Data
- Scalability: SageMaker allows you to handle large datasets and perform complex analyses without worrying about infrastructure management.
- Flexibility: JSON’s flexible structure allows for easy adaptation to different use cases, and SageMaker’s support for custom scripts ensures that you can tailor the analysis to your specific needs.
- Integration: SageMaker integrates seamlessly with other AWS services like S3, Lambda, and DynamoDB, making it easy to create end-to-end machine learning pipelines.
Conclusion
AWS SageMaker provides a robust platform for performing data analysis on JSON data, offering tools for data preprocessing, model training, deployment, and real-time predictions. Whether you’re dealing with simple flat JSON data or complex nested structures, SageMaker’s flexibility and scalability make it an excellent choice for building and deploying machine learning models. By leveraging SageMaker, businesses can unlock valuable insights from their JSON data, driving smarter decision-making and improving overall outcomes.





{kind=link}